")
初识推荐算法
按 这里 的基本思路是:
+ 阅读《深度学习推荐系统》,作者王喆,入门基础知识
+ 熟悉推荐系统中的流程:召回->粗排->精排-->re-rank;以及各个流程中常用的算法
+ 了解推荐模型的整个发展历史,了解每个模型的结构、优缺点、改进方式(看看代码)
+ 考虑一些推荐系统的实际问题,多看看知乎大佬们的回答:
1.冷启动问题
2.exploit-explore问题
3.样本稀疏
4.多目标
5.特征泄漏
6.离线训练和流式训练指标不一致
7.等等
然后找到一个 推荐系统学习笔记 的专栏,前面基本是一些细节,11 和 13 为更宏观的视角。
推荐系统架构
推荐算法属于推荐系统中最重要、最核心的一环,可以高度概括为 f(U,I,C)。
这个极简定义源于推荐系统核心要义:基于用户(User)+ 物品(Item)+ 场景(Context)信息,从系统中的物品库中,给对应的用户推荐相应的物品,也即实现所谓的「千人千面」。
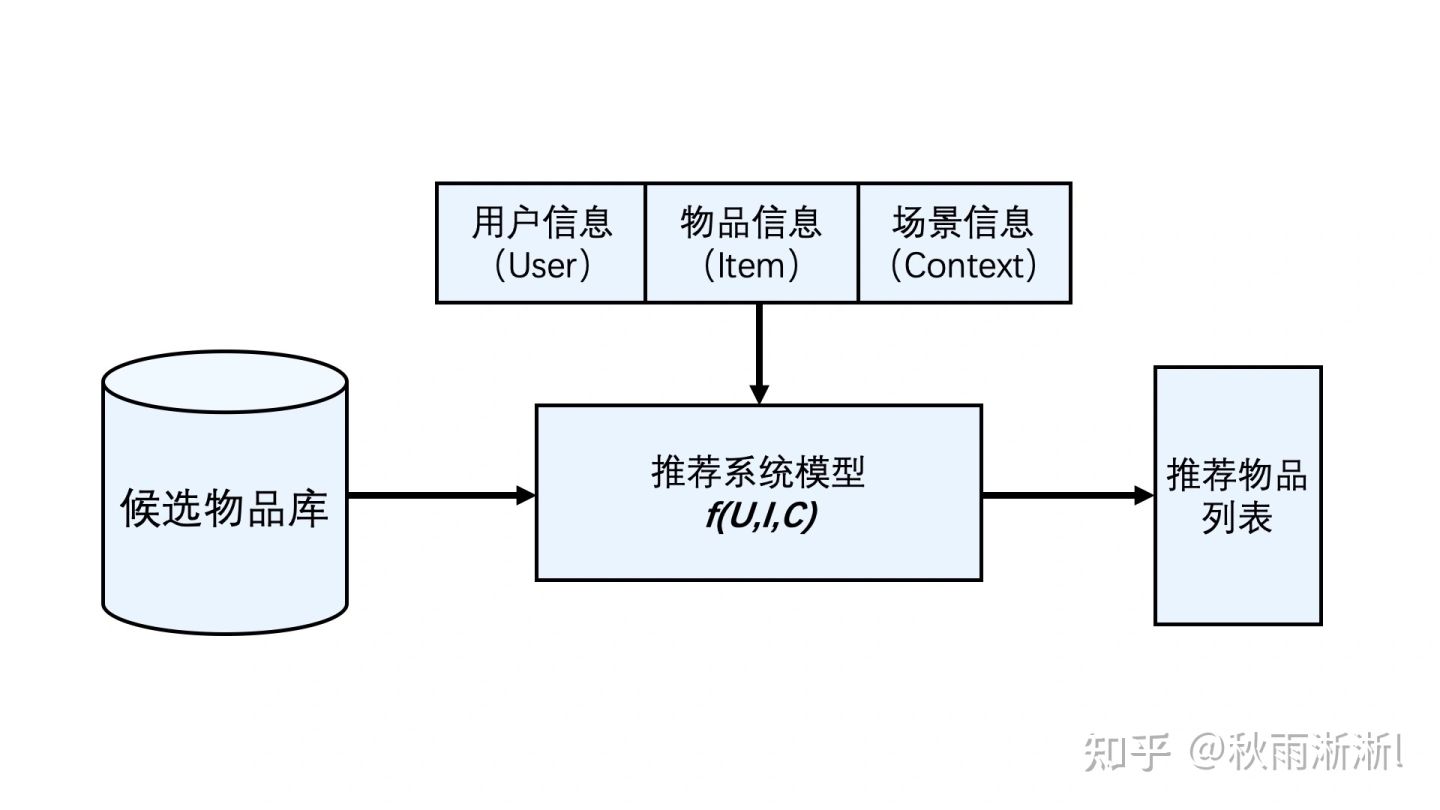
推荐系统的一次推断流程:
- 读取 User、Item、Context、候选物品库数据(ETL)
- 算法模型打分(有算法模型,意味着存在模型训练的过程)
- 推荐结果展示(按打分结果排序)
复杂一点的 Netflix 推荐架构:
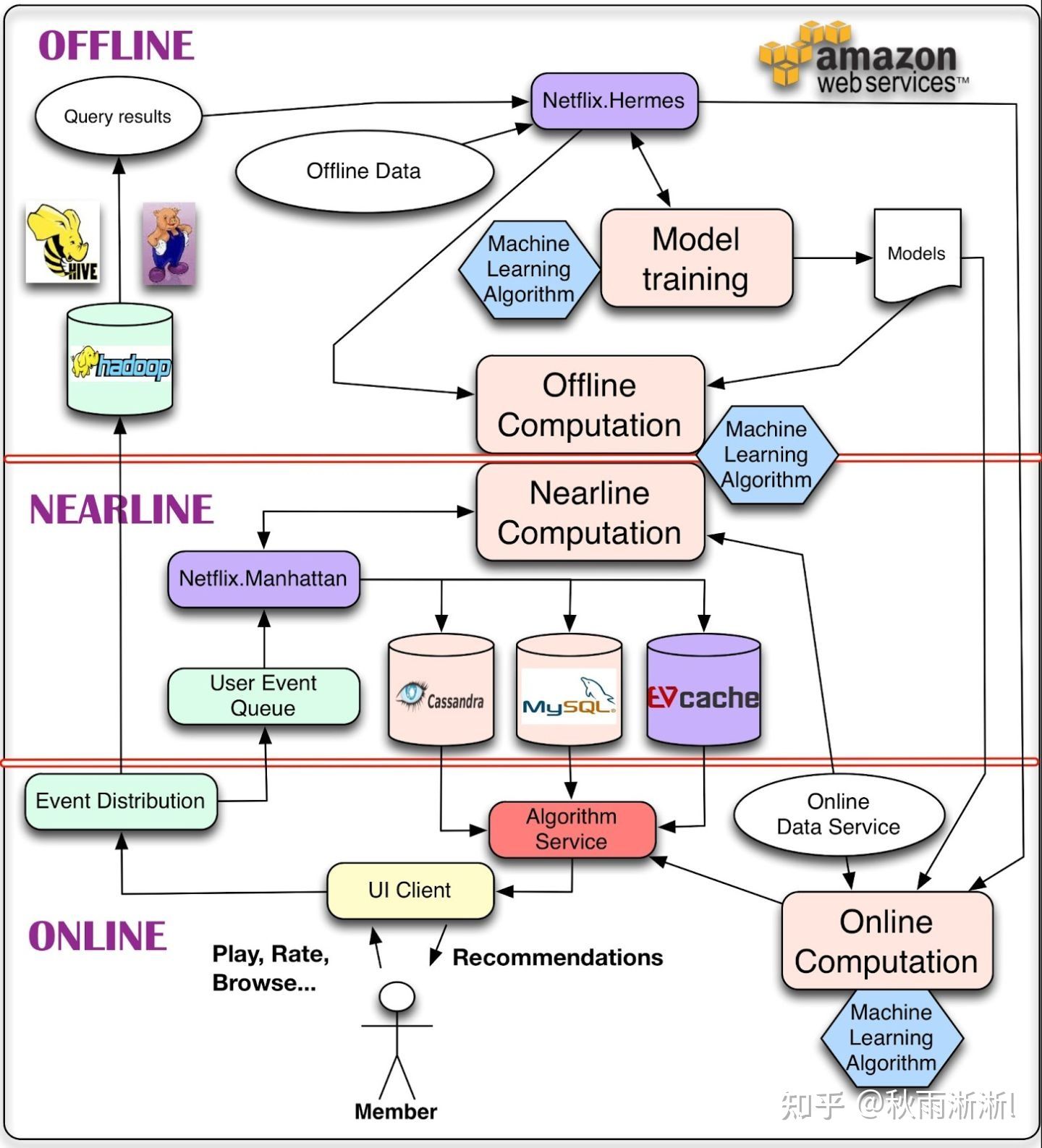
分三个部分:
- 离线:在这个阶段对数据读取的响应速度没有很高的要求,只要保证数据可达即可
- 近线:把算法模型所需要的特征数据,存储到读取时延更低的 Cassandra / MySQL 等中,在数据获取上减少推断时延,并保证特征和模型的实时性
- 在线:基于用户属性+场景信息对召回活动做在线打分,并把结果推荐给用户(整个环节需要在100ms这个量级内完成)
于是细化后的流程:
- 读取 User & Item(离线+近线+在线)、Context(离线+在线)、候选物品库数据(在线)
- 算法模型训练(离线训练+近线迭代)
- 算法模型打分(在线)
- 推荐结果展示(在线)
- 记录用户和推荐系统的交互日志(在线+近线+离线)
2021 的视角:
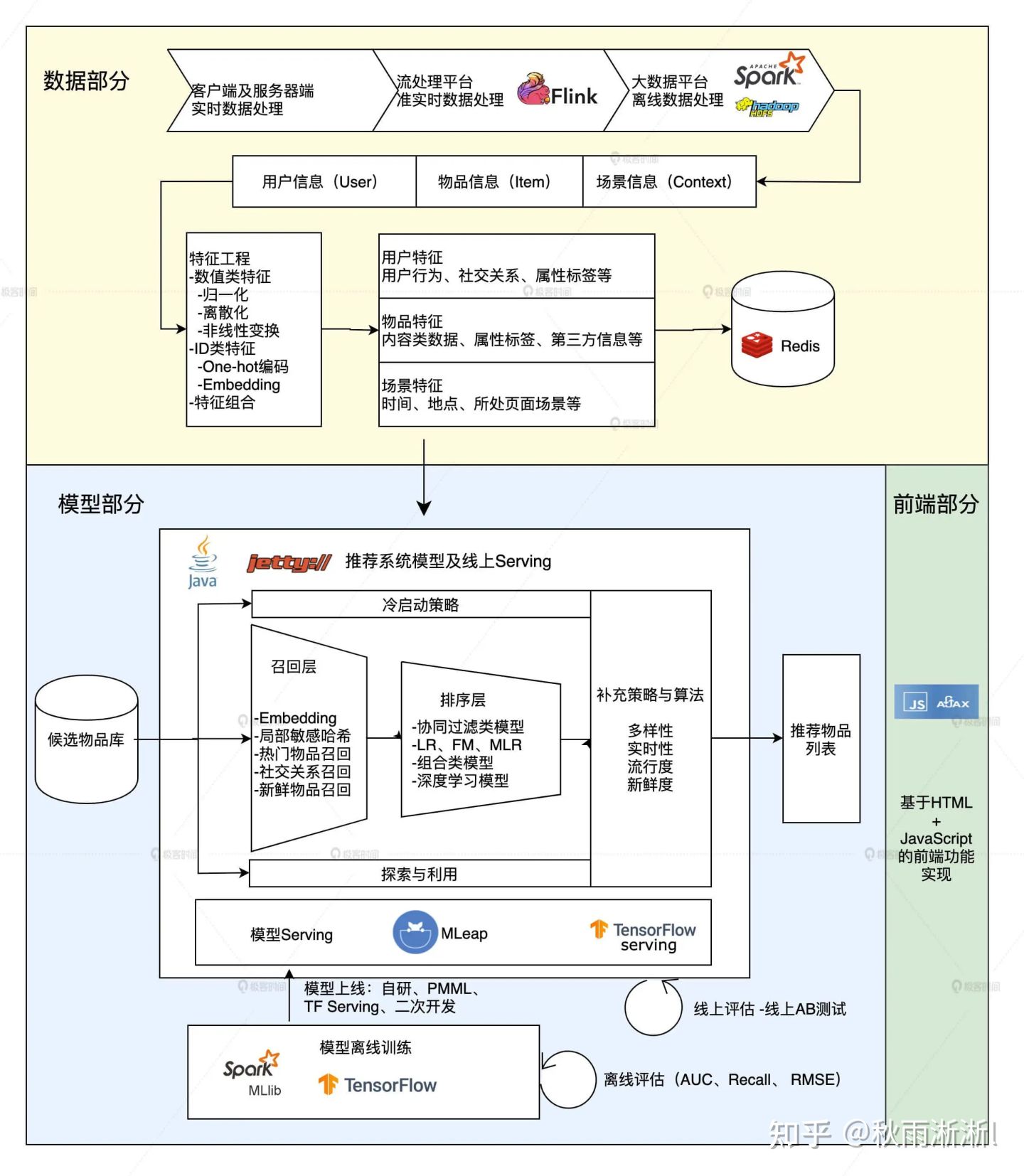
于是再次细化添加:
- 读取数据:对上述数据做离线做特征工程,然后导入近线和在线层数据库
- 算法模型打分:存在召回+排序+重排三个阶段
- 线上效果评估:AB Testing
AB Testing 通常流程:
- 在线上的流量池中,切出一部分流量来给A算法(我们令这么份流量为实验组)
- 同时为了方便对,我们也会切出等量的流量来给B算法(同样我们令这份流量为对照组)
- 让这两个算法分别再各自的流量中运行一段时间,看看最终在线CTR/CVR等商业指标的表现情况如何。
回来精简一下:
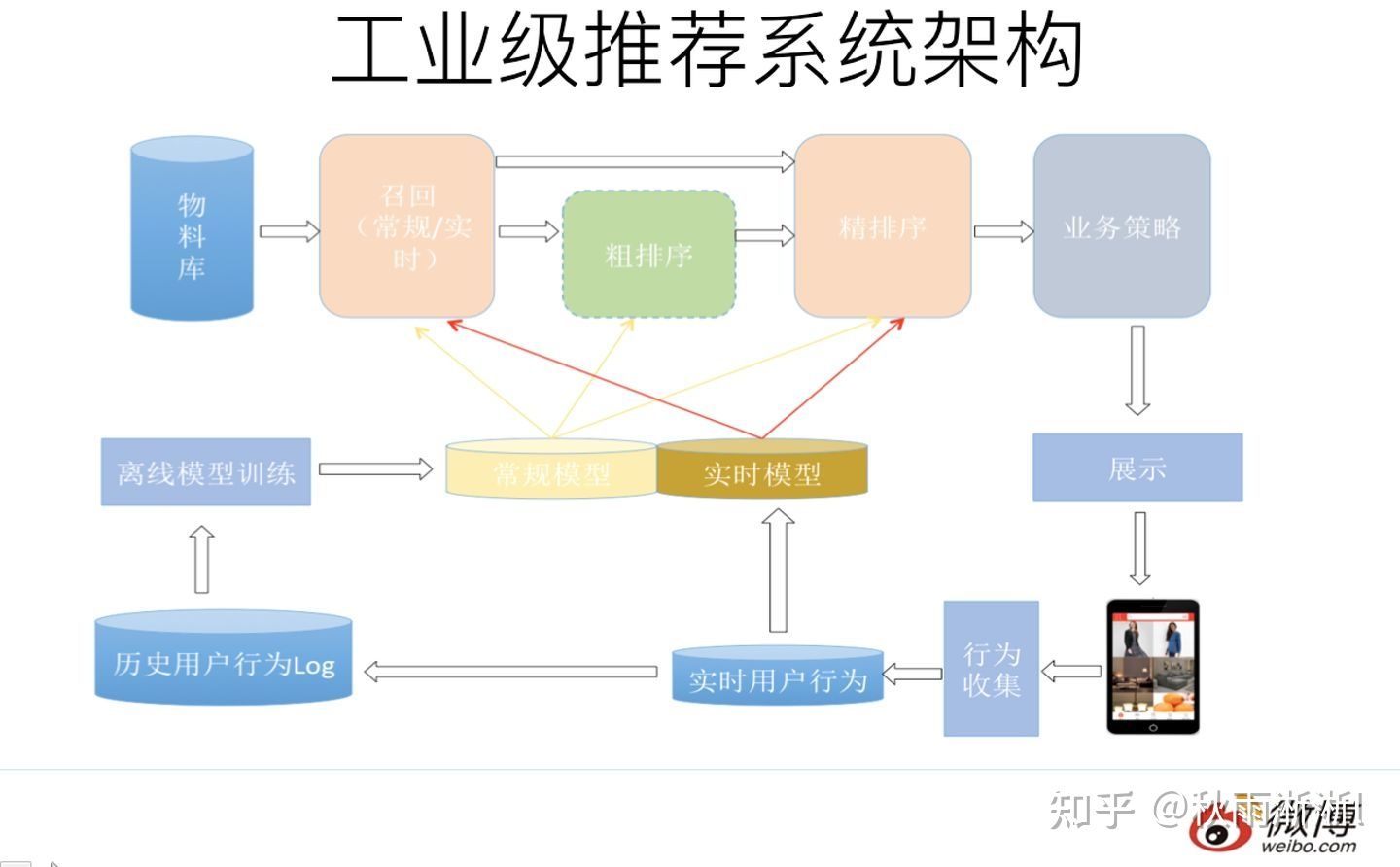
推荐系统架构中的召回算法
大型的推荐系统一般由召回、粗排、精排和重排四部分组成,推荐召回在最底层。
召回决定了推荐效果的上限,意义是在百万级全库物料中,快速的筛选出用户感兴趣的物料给到粗排层。
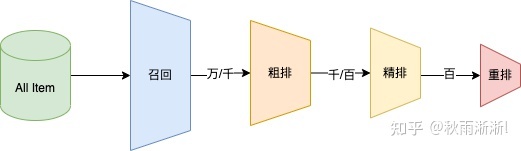
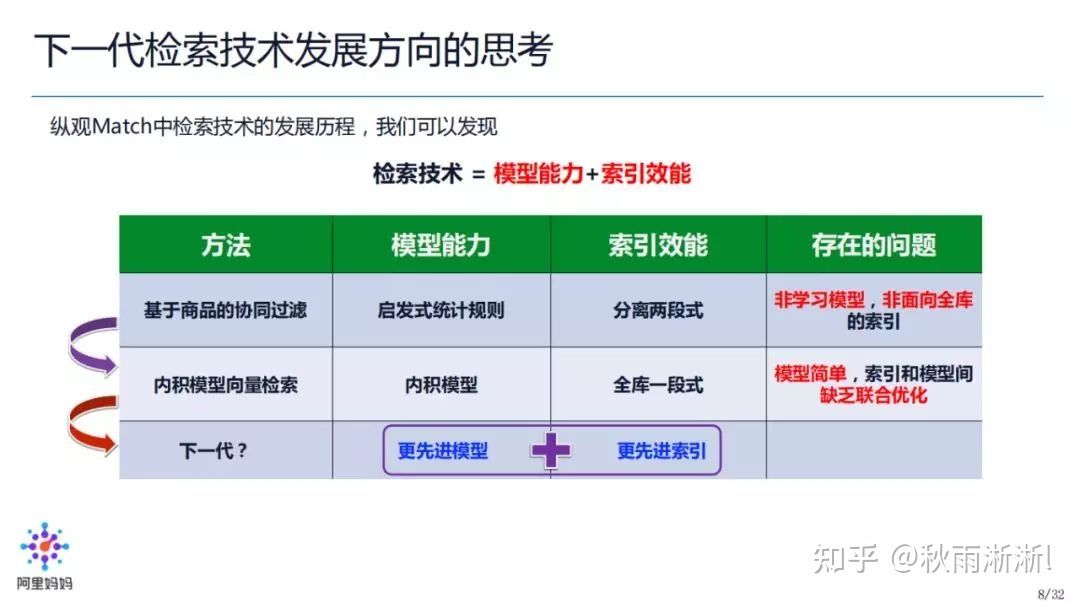
可以采用多路召回,具体办法有规则召回、协同召回、向量召回、树召回等。
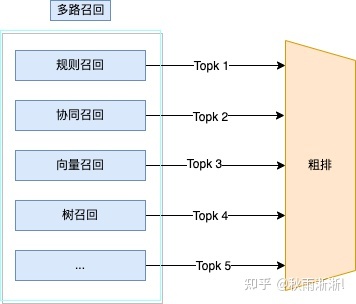
规则召回实现简单、具备良好的解释性、能较为准确的控制数量、能保证一定的质量、能在非常短的时间内完成召回过程。
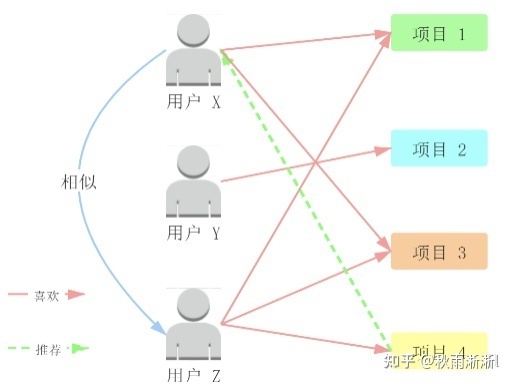
协同召回易于实现、工程实现成本低、具备一定的个性化召回能力、具备良好的算法解释性、可拓展出多种召回形式。
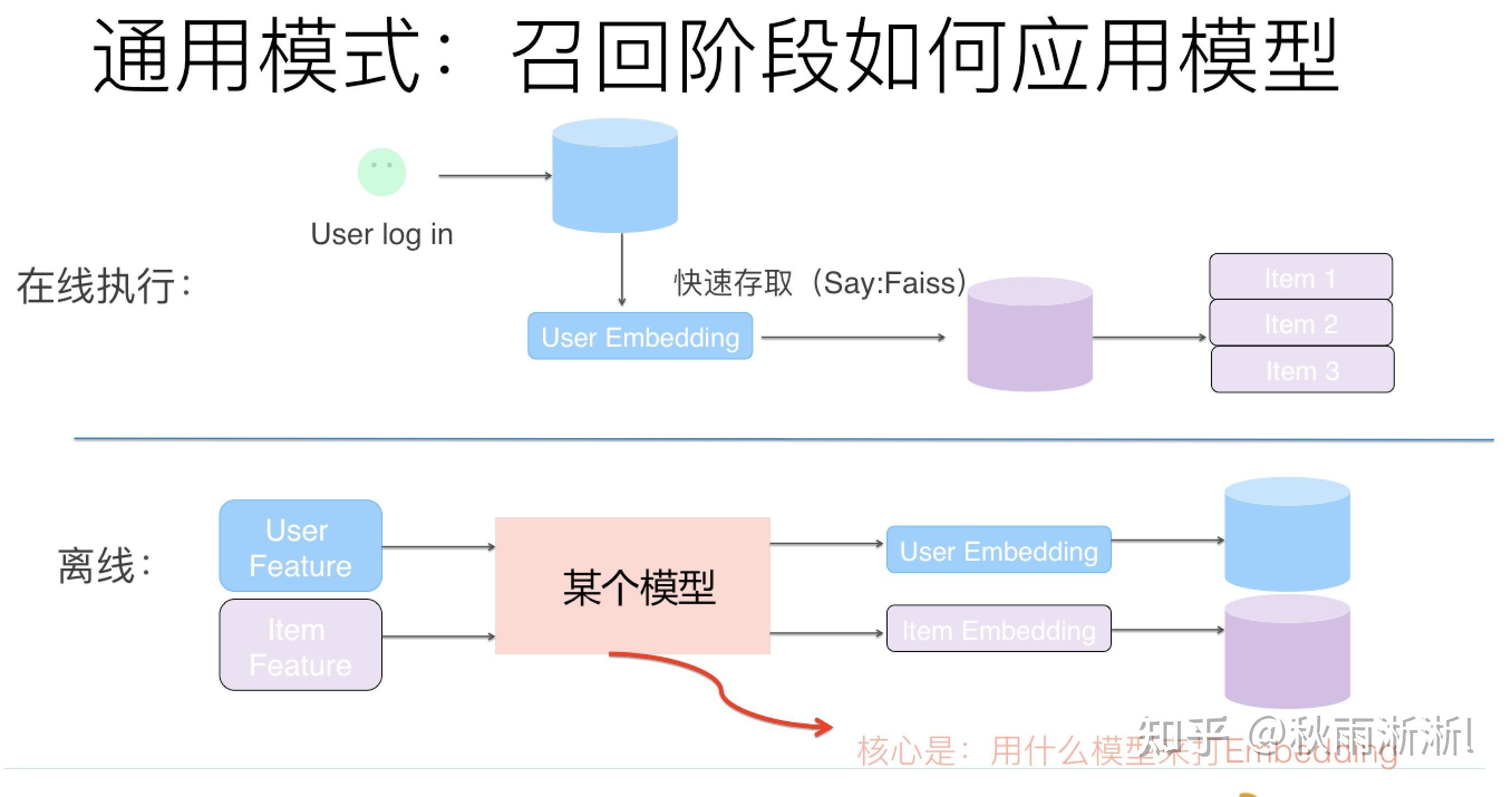
向量召回的核心思想是通过模型训练出用户物料的向量,从而进行向量相似召回。
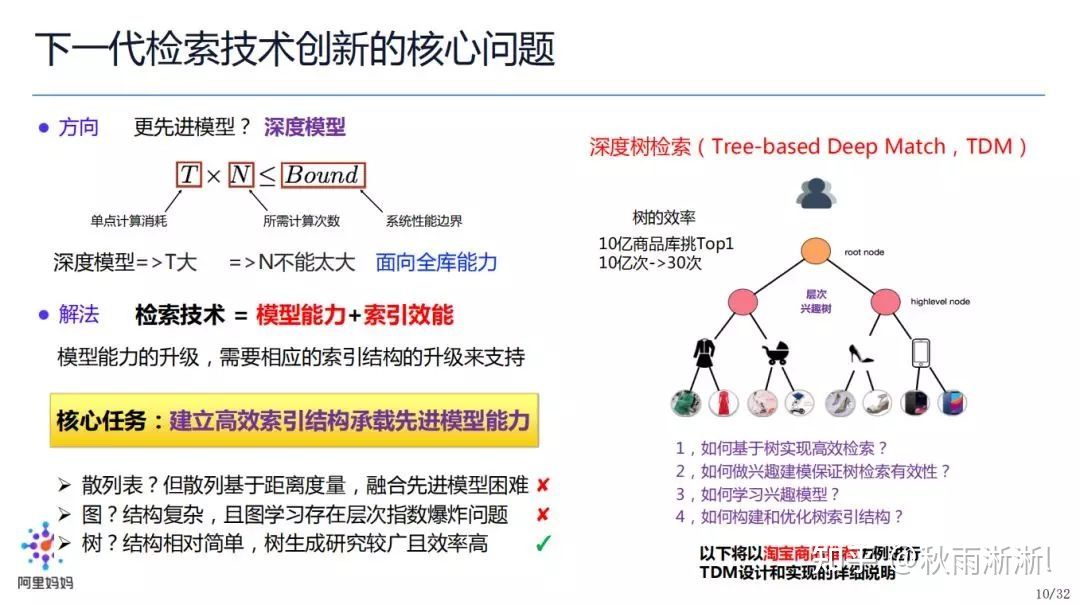
树召回(Tree-based Deep Match)深度树匹配的建模思路:
把所有 item 商品库聚合成为一个层次的兴趣树,树的叶子节点为具体的活动,中间节点则代表不同层次(粒度)的兴趣聚合体,这样召回则变成了从商品库里面的检索转换成一个在树上做检索的过程。
知乎上的一些问题存档
- 推荐算法的就业前景如何?:红海,比起 NLP(自然语言处理)建议 CV(计算机视觉)
- 如何从cv转推荐算法?
- 推荐算法岗是否存在严重人才过剩?
- 推荐算法会产生哪些负面影响?
- 想成为一名推荐算法工程师,有什么学习路线和规划?:请放弃,路线就是放弃算法转开发,或者放弃计算机转金融
- 知乎推荐算法会毁了知乎吗?
- 广告算法和推荐算法哪个更好?推荐转行广告是否可行?
- 李彦宏批评推荐式算法,你怎么看?
- 我想请教一下,做推荐算法或者自然语言处理,一个中等211想进大厂 需要什么加分项才能比较有把握?
- 网易云音乐的歌单推荐算法是怎样的?
看到 这个回答:
1、网易云的推荐算法基础是基于协同过滤,极大可能有通过标签二次过滤。
2、推荐系统分析的行为有播放、下载、收藏歌曲。可能存在行为叠加。
3、对用户不完整播放的行为不敏感,这个应该算是缺点吧。
4、总的来说,推得还算准确。但是推荐算法不算太先进。大家觉得准确,可能是由于网易云使用的用户人群属性较单一,对于推荐算法来说这样的人群是十分理想的。QQ音乐新猜你喜欢,自我颠覆的个性化推荐系统,有兴趣可以去参考下QQ音乐的推荐系统,在对用户行为的分析上,会更完善。
倒觉得「对用户不完整播放的行为不敏感」是优点。
首先如果你是一个产品经理,首先你要思考:你的业务适合做推荐系统吗?